Learn to Pay Attention
06 May 2018
TL;DR
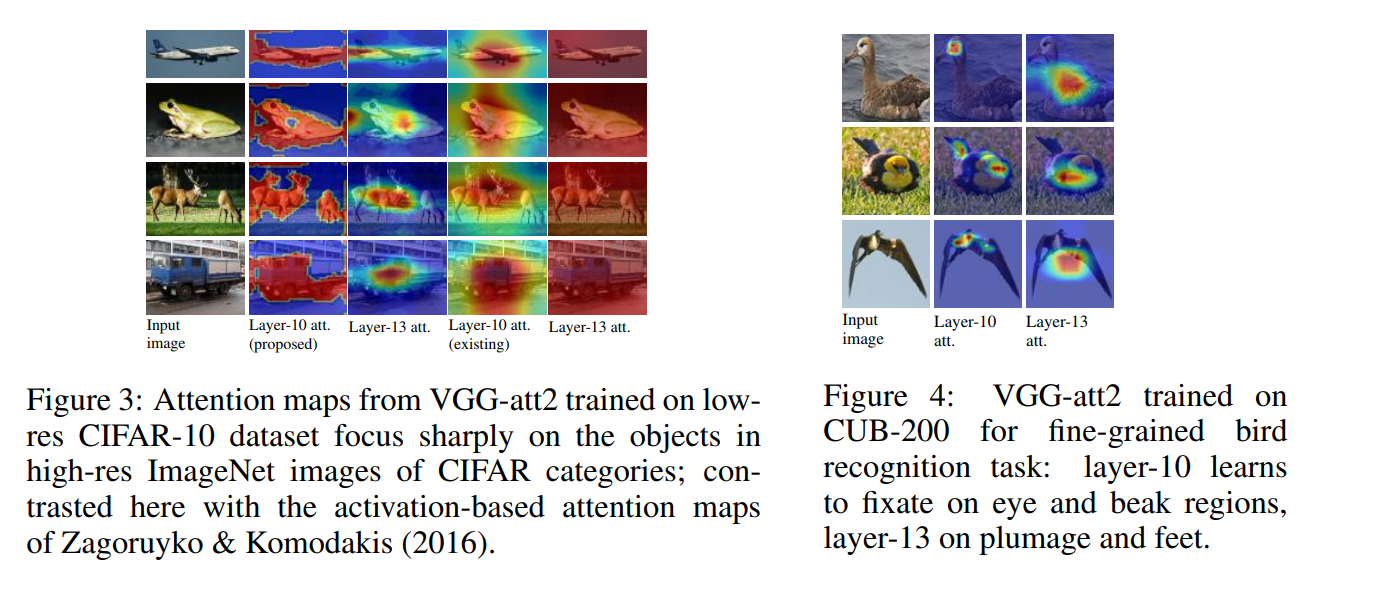
- 目標はSaliency Mapを使ってCNNが分類を行うときに使う有効な視覚的情報の空間的なサポートを見つけ出し,利用すること
- Saliency Mapを用いることで有効な領域の情報を重視し,無関係な情報を抑制する
- Local feature vector (CNNの中間層の出力)とGlobal feature vector (CNNの後段のFCの出力)を組み合わせる
- 適合度によって重要なLocal feature vectorだけを分類に活用する
構造
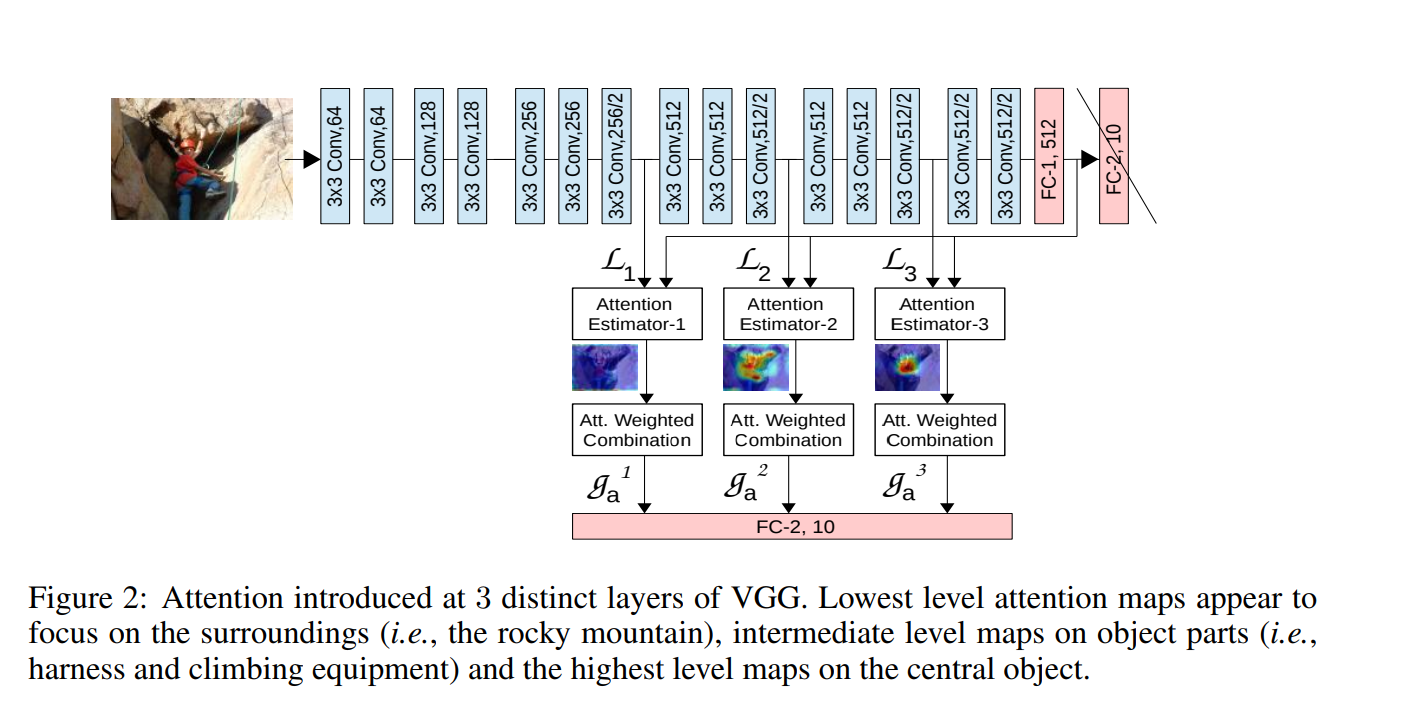
$S$個のAttention Moduleを持っている.
$s$個目のAttention Moduleは,長さ$M$のベクトル$N$個からなる集合である.
ここで,ベクトルの長さ$M$はFeature Mapのチャネル数に等しく,ベクトルの個数$N$はFeature Mapの画素数に等しい.
$L^s$のshapeは,$(BS, N, M)$
各ベクトルの長さをFC-1の出力$\bold{g}$の長さ$M’$に揃える
$\hat{L^s}$のshapeは,$(BS, N, M’)$
Compatibility scoresを求める
$C^s(\bold{\hat{L_s}}, \bold{g})$のshapeは,$(BS, N)$
Compatibility scoresをSoftmaxで正規化する
各Moduleの出力$\bold{g^s}$は
最終的には,全Moduleの出力を連結することでModule全体の出力として,最後にFC層