TGANv2 Efficient Training of Large Models for Video Generation with Multiple Subsampling Layers
27 Nov 2018
TL;DR
- GANにおいて,Generatorのtop に近い部分はパラメータ自体は少ないのに,計算量とメモリを消費しているので,そこを効率的にした
- 実験はGANで動画生成で行われているが,その他のデータセット,手法に対しても有効そう
手法
Generatorは,2つの演算の合成から成り立っていると定義.
- $g^A$: abstract block. bottomの方のBlock.パラメータは多いが,計算は軽い
- $g^R$: rendering block. topの方のBlock.パラメータは少ないが,計算は重い
rendering block の計算が重いので,abstract block によって計算された,abstract map を Subsampling layer $S^G$ によってsubsampling(論文内では,矩形の大きさ固定のクリップ) する.
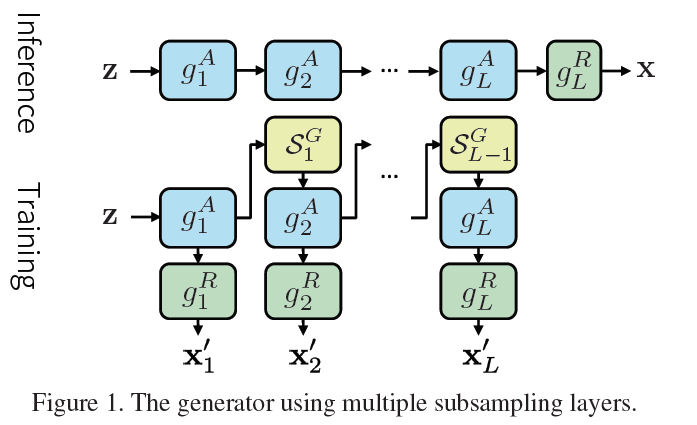
これにより,計算量が緩和されるが,計算量と生成精度のトレードオフが発生するので,多段のabstract block, rendering block, Subsampling layerを導入.
それぞれの$g^R_l$から,生成サンプルが出力されるので,DiscriminatorもL個存在する.
最終的なDiscriminators の出力は,
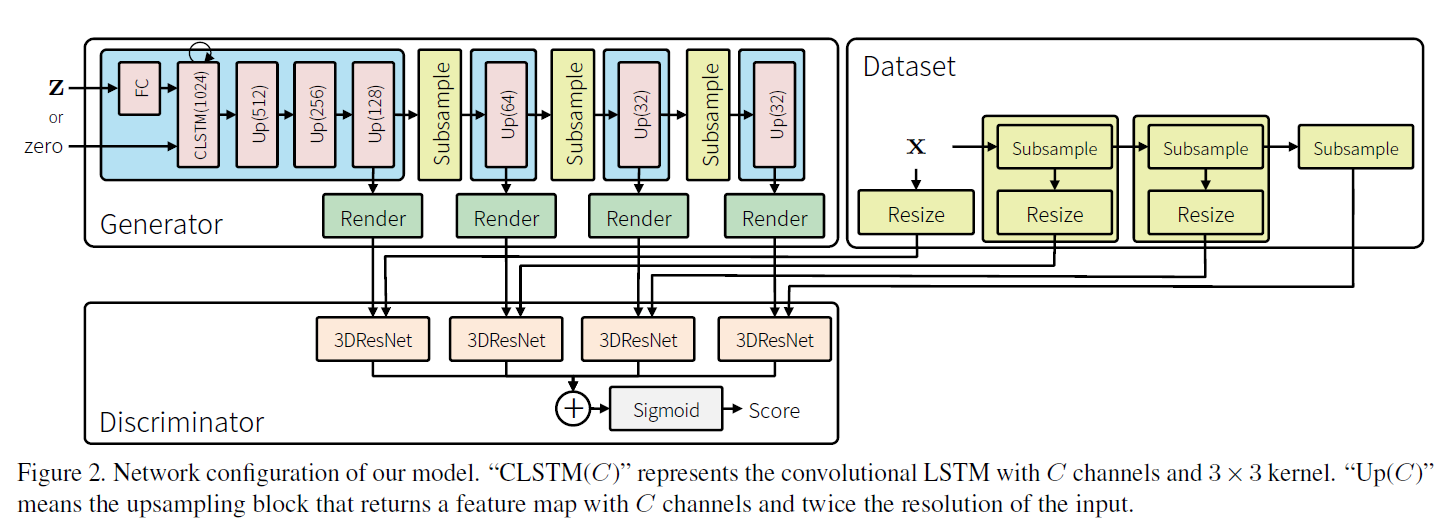
また,abstract map に関するSubsamplingだけでなく,ミニバッチの中から,サンプルを徐々に取り除いていく,Adaptive batch reduction も導入.
考え的には,Generatorのtop は計算こそ重いが,パラメータとしては少ないので,少ないサンプルでも学習できる.さらにBatchsizeを大きくできるので,diversity が確保できる.
