
1. どんなもの?
- pretrained modelを用いたUnsupervised Anomaly Detection
- 正常状態のPatch特徴を効率的にメモリ内に保存
- Topに近い特徴量を使用しないことでImageNetのバイアスを低減
2. 先行研究と比べてどこがすごい?
- Mahalanobis ADみたいにkNNを使う手法は計算時間が長い
- 重要な情報のみをメモリに残すことで解決
- Topに近い層から数層の特徴量を持ってくると,ImageNetのバイアスがある
- 中間くらいの層からのみ特徴を持ってくる
3. 技術や手法の"キモ"はどこ?
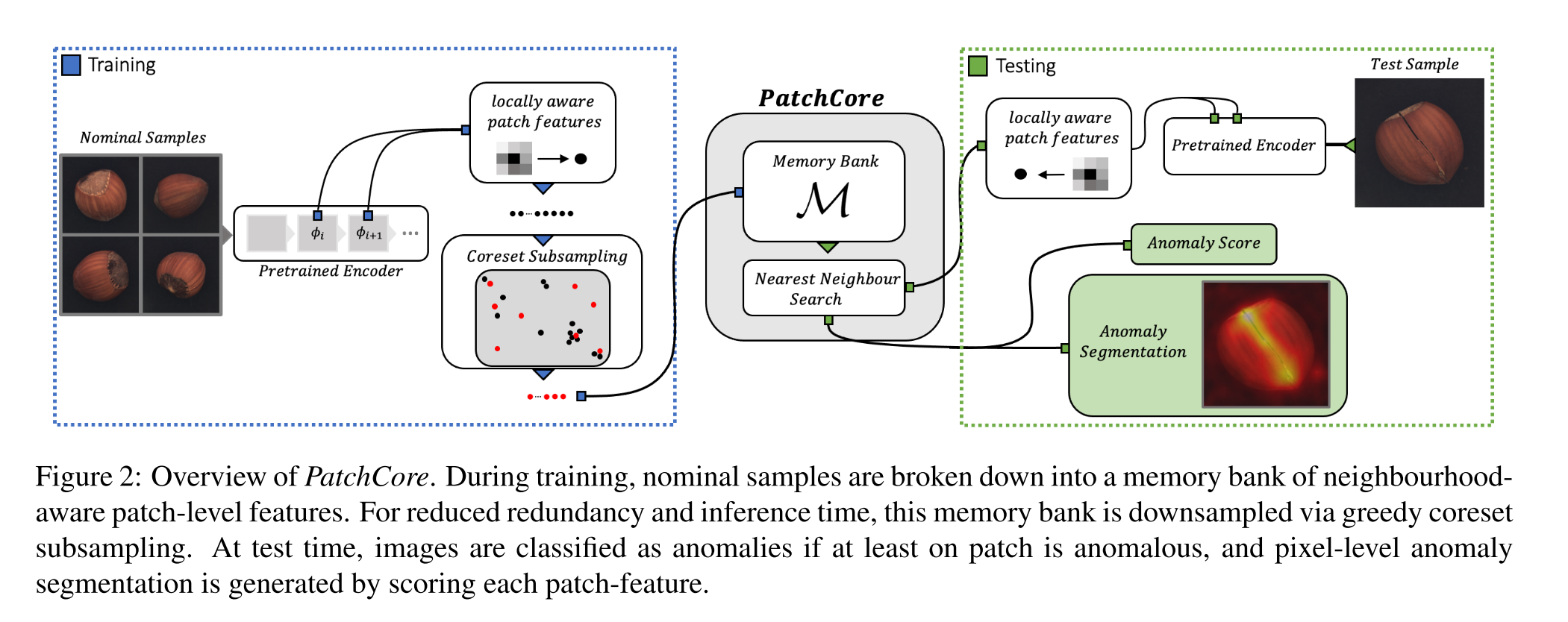
- patch featureのcoreset (重要な情報のみのmemory bank)を形成する

変数の定義
| sybmol | description |
|---|---|
| $x_i$ | i番目の入力画像 |
| $\phi_j(x_i) = \phi_{i, j} \in \mathbb{R}^{c^* \times h^* \times w^*} $ | pretraind model $\phi$の$j$層目の特徴量 |
| $\phi_{i, j}(h, w) = \phi_j(x_i, h, w) \in \mathbb{R}^{c^*}$ | $\phi_{i, j}$の位置$(h, w)$の特徴ベクトル |
| $p$ | パッチサイズ |
| $f_{agg}$ | average poolingなどの近傍のfeatureを集約する関数 |
| $\psi \colon \mathbb{R}^d \rightarrow \mathbb{R}^{d^*} $ | random linear projections |
学習
Locally aware patch features
-
パッチの近傍を定義
-
そのパッチに対応するfeatureを定義
- $f_{agg}$はaverage poolingなどの近傍のfeatureを集約する関数
-
$\phi_{i, j}$から生成されるpatch featureの集合を定義
-
Patchcoreでは$j$層目の特徴と$j+1$層目の特徴をresize & concat
-
全訓練データ(正常)の特徴メモリバンクを定義
Coreset-reduced patch-feature memory bank
- SPADEのように全サンプルに対して,距離計算するのは時間がかかる → coresetを生成して短縮したい
- coresetの定義
- $\mathcal{M}^*_c$ はNP-hardなので,iterative greedy approximationで近似

推論
-
$x_{\text{test}}$のパッチ特徴集合$\mathcal{P}(x_{\text{test}}) = \mathcal{P}_{s,p}(\phi_j(x_{\text{test}}))$のそれぞれとcoreset内で最も近い特徴ベクトルを探し,その中でも最も距離が大きいものを求める
-
その時の最大距離$s^*$は
-
近接パッチの情報を考慮したimage-levelの異常度は
- $\mathcal{M}$内の の$b$個の近傍パッチの集合を$\mathcal{N}_b(m^*)$とすると
-
patch-levelの異常度は
4. どうやって有効だと検証した?
- MVTec で実験
- Image-levelでSoTA
- %はcoresetの大きさ



- 近傍サイズとどの層の特徴を使うとよかったか → 近傍サイズ3,層は2+3(topから)
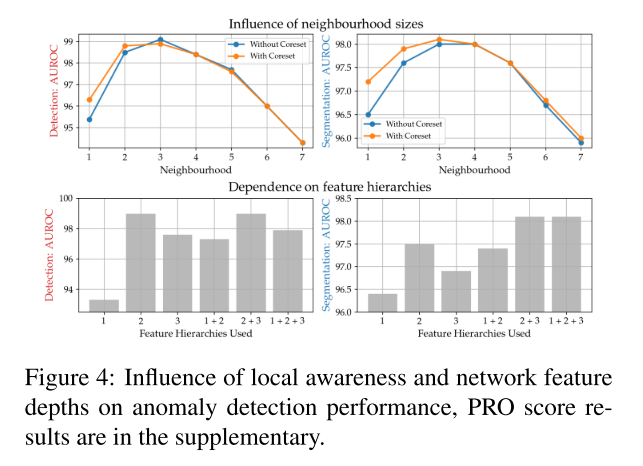
- SPADEよりも高速,PaDiMと同等

- 正常サンプルの数が減っても強い

5. 議論はあるか?
- SoTA更新
- min maxがいっぱいあるが,非公式実装は正しく実装できているか?