
1. どんなもの?
- Vision Language Model(VLM)を使ったZeroshot Anomaly Detection
2. 先行研究と比べてどこがすごい?
- Zeroshotで異常検知が可能
- 大量の画像・テキストで学習済みのモデルを使用
- 新たに学習を行わない
- 直接的に異常スコアを算出可能
- WinCLIPはあくまでtext-visual similarity
3. 技術や手法の"キモ"はどこ?
- GroudingDINOを使って,異常領域矩形の検出
- 異常領域矩形をクエリにSegment Anythingで異常領域を算出
- 算出した異常領域を3つのフィルタリングでRefine
- 対象の面積
- 特徴マップのSaliecncy
- 異常度のTop-k
- 入力テキストをclass-agnostic,class-specificで組み合わせる
Segment Any Anomaly(SAA)
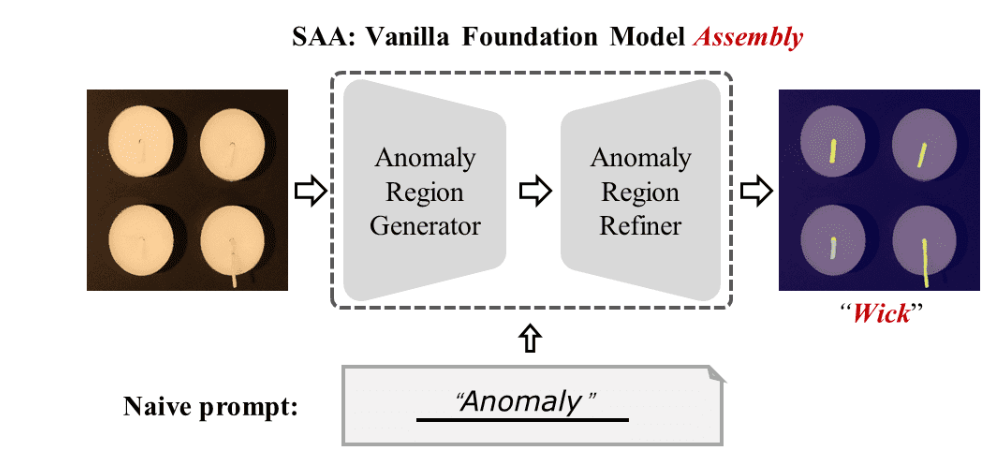
- 筆者らが最初に考えたモデル
- GroudingDINOを使って,スコアと異常領域矩形の検出.(入力は画像とテキスト)
- 異常領域矩形をクエリにSegment Anythingで異常領域を算出
- まとめると,SAAでは画像とテキストを入力すると,異常領域とそのスコアが算出される
- ここで言語の曖昧性(language ambiguity)という問題
anomalyなどの抽象的な単語では精度がよくない
SAA+
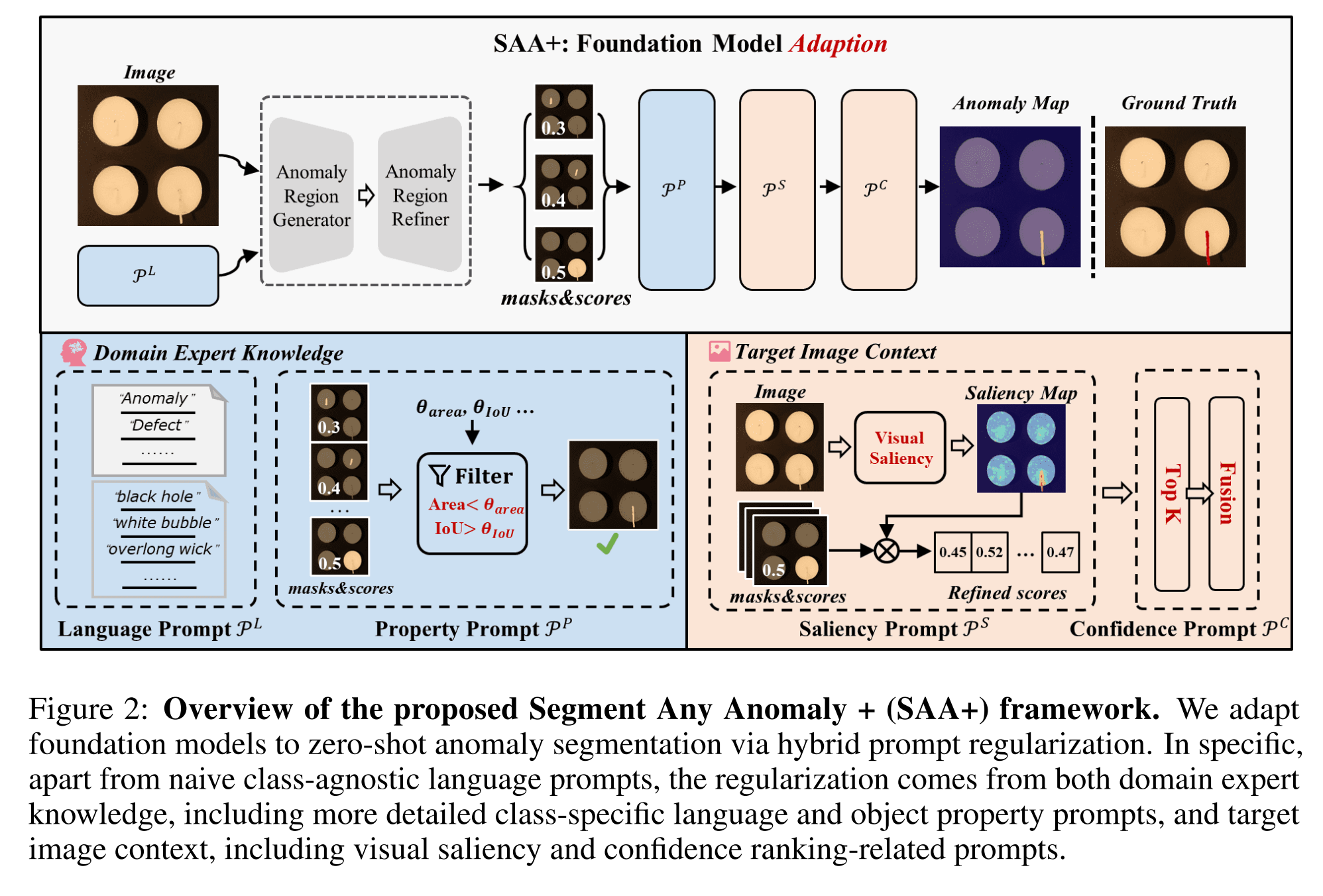
入力に対する工夫
Anomaly Language Expression as Prompt
- 言語の曖昧性をなくすために2つの種類のテキストを入力にする
anomalyなどのclass-agnosticなテキストblack holeなどのclass-specificなテキスト
フィルタリングでRefine
Anomaly Object Property as Prompt
- 異常の大きさは対象物(ワーク)よりも小さく,さらに面積値は一定以下であるという制限を設ける
Anomaly Saliency as Prompt
anomalyなどのテキストはドメインごとにGapがあるので,画像特徴から顕著性が高い箇所だけを引き抜く- 事前学習済みモデルから特徴マップを抽出し,特徴ベクトル間の内積を算出.その後,N近傍(内積が近い順)との内積を算出し,1から引くことで顕著性にする
- 元の領域と顕著性スコアを掛け合わせ
- SAAのScoreと↑のScoreを掛け合わせ
Anomaly Confidence as Prompt
- 異常領域は多くてもこのくらいだろうという制限をかける
- ↑で算出されたスコアをもとに面積値フィルタリングしたmaskからTop-k
- 最終的な異常度を算出
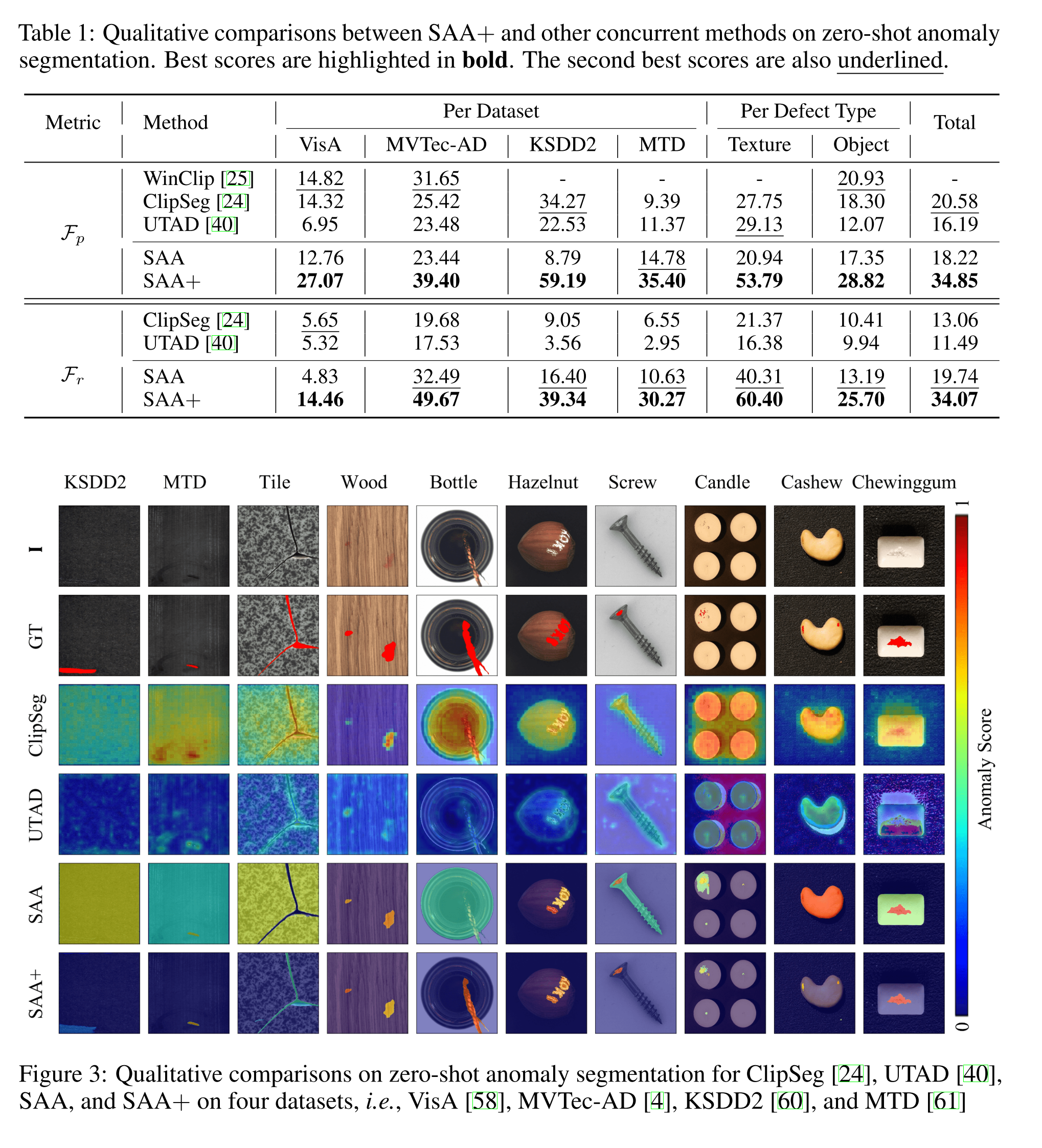
4. どうやって有効だと検証した?
- VisA, MVTec-AD, MTD, KSDD2で実験
- 評価指標は
- max-F1-pixel ($F_p$): 最適なしきい値を設定した際の最高のピクセル単位のF値(WinCLIPが採用)
- max-F1-region ($F_r$): 最適なしきい値を設定した際に予測マスクと正解マスクが一定値以上オーバーラップしているかのF値(一定値は0.6を採用,この論文独自)
- SAA+はWinCLIPやSAAより高い精度で異常検知可能
5. 議論はあるか?
- Zeroshotでそこそこの性能が出ているが,検査画像や検査用テキストがWeb上にいっぱいあると思えないので,追加で正常/異常を覚える機構は必要
- 独自データでやった感じ,複雑な形状・構成の画像はその複雑な形状や部品構成で異常判定してしまう
6. 次に読むべき論文はある?
- Cao, Y., Xu, X., Sun, C., Cheng, Y., Du, Z., Gao, L., & Shen, W. (2023). Segment Any Anomaly without Training via Hybrid Prompt Regularization. https://arxiv.org/abs/2305.10724
- Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Li, C., Yang, J., Su, H., Zhu, J., & others. (2023). Grounding dino: Marrying dino with grounded pre-training for open-set object detection. ArXiv Preprint ArXiv:2303.05499.